(↗: external link) thank you Unite.AI, 徐土豆, and AIPaperPodcasts for featuring relsim :)
Thao: "I created 2 videos, but can't decide which one is better 😭 So I will put both here 😂"[video-version-1] [video-version-2]
TL;DR:
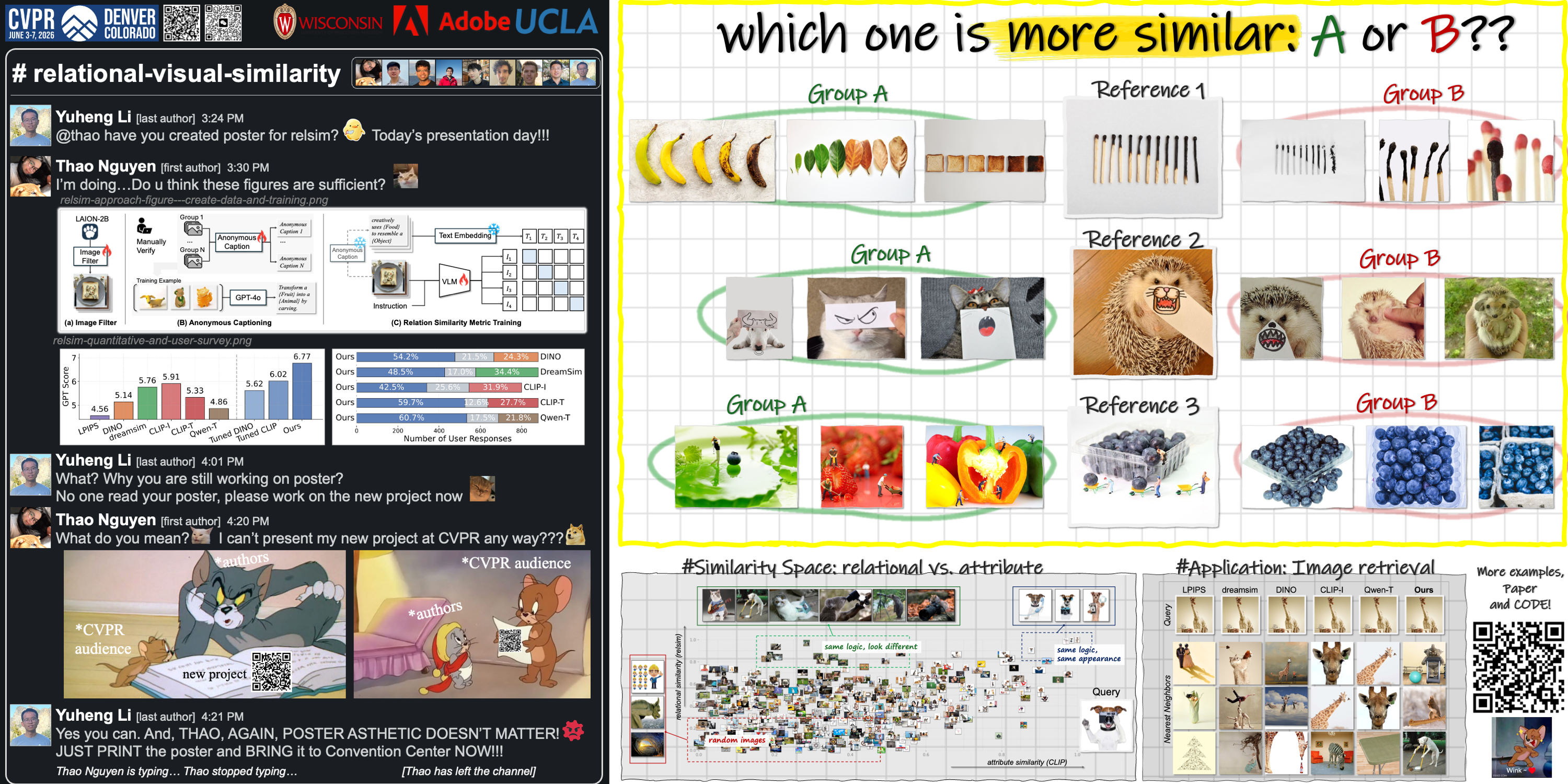
We introduce a new visual similarity notion: relational visual similarity (relsim), which complements traditional attribute similarity (e.g., LPIPS, CLIP, DINO).
📜 Abstract
Humans do not just see attribute similarity---we also see relational similarity.
This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species.
Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive.
An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit.
[reveal all] [hide all](Above figure is modified from original version created by Chad Edward (thank you Chad!); original image link: Plate Tectonic Metaphor Illustrations (CMU))
How can we go beyond the visible content of an image to capture its relational properties?
How can we bring images with the same relational logic closer together in representation space?
To answer this question, we first formulate relational image similarity as a measurable problem:
two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ.
We then curate 114k image-caption dataset in which the captions are anonymized---describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision Language Model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it---revealing a critical gap in visual computing.
⚒️ Usage Example
This is the example usage of the relsim. For more details, please check:
github/relsim
.
This code is tested on Python 3.10: (i) NVIDIA A100 80GB (torch2.5.1+cu124) and (ii) NVIDIA RTX A6000 48GB (torch2.9.1+cu128).
Other hardware setup hasn't been tested, but it should still work. Please install pytorch and torchvision according to your machine configuration.
We present a qualitative gallery of image retrieval results using (i) attribute-based metrics (e.g., LPIPS, CLIP, DINO) and (ii) relational-based metrics (ours: relsim).
🔍 Dataset Viewer
This is a data viewer for the datasets used in the paper. Please click on the image to view the corresponding dataset.
You can also see the dataset on HuggingFace.
Believe it or not, we spent months struggling to recreate this theoretical figure (yes we did!),
... and ... after ... a lot of effort ... to ..... pull ..... things .....together .......... We finally made it!
Click to reveal
After almost 30 years, thanks to relsim, the theory can now be brought to life!
Cool, isn’t it?? (˵ •̀ ᴗ - ˵ ) ✧
📚 Citation
@misc{nguyen2025relationalvisualsimilarity,
title={Relational Visual Similarity},
author={Thao Nguyen and Sicheng Mo and Krishna Kumar Singh and Yilin Wang and Jing Shi and Nicholas Kolkin and Eli Shechtman and Yong Jae Lee and Yuheng Li},
year={2025},
eprint={2512.07833},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.07833},
}
 nal Visual Similarity
nal Visual Similarity 2.
2.  3.
3. 
 Did You Know??
Did You Know??
 Article↗ (by Unite.AI)
Article↗ (by Unite.AI)
 Blog Post↗ (by 徐土豆)
Blog Post↗ (by 徐土豆)