Personal AI Agent
for Camera Roll VQA
explore
The project lives across a paper, a conversational agent, a benchmark dataset, and two interactive pages — a live question board and an agent demo. Pick where you'd like to start.
abstract
We study the personal AI agent for camera roll VQA setting. In this setting, a conversational AI assistant can access a user's personal camera roll and retrieve relevant photos to answer queries, ranging from simple factual questions (e.g., "Name of the food I tried yesterday?") to more open-ended ones (e.g., "Recommend some dishes I have never eaten before").
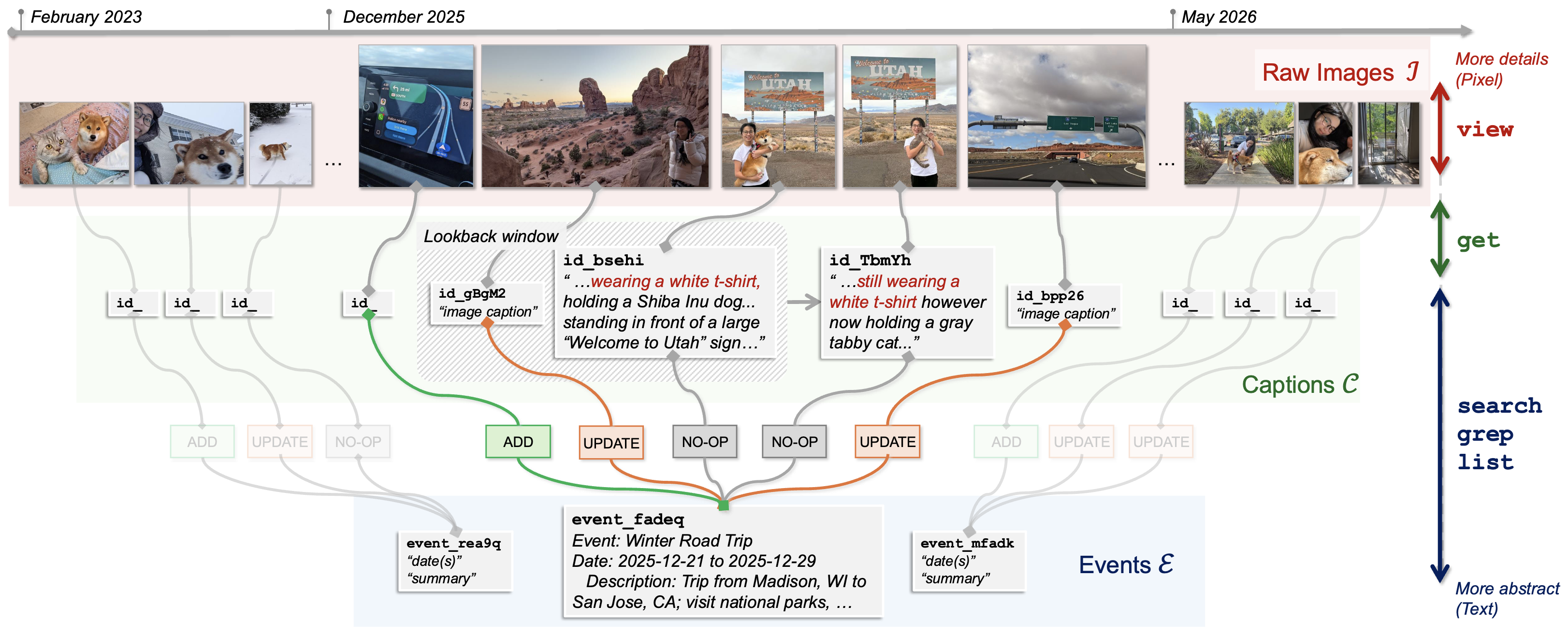
Given the vast nature of the personal camera roll — multiple years, hundreds to thousands of photos — a successful AI assistant needs to understand a long-horizon, highly personalized visual content stream in order to navigate and locate the correct and/or relevant information. To support this, we collect and manually annotate questions that mimic real-world usage. The final dataset, camroll, contains 50 users, 31,476 images, and 2,500 QA pairs.
We further design camroll-agent, a conversational AI agent equipped with hierarchical memory and a minimal set of tools for efficient navigation over large, personalized visual memory. Experimental results show that camroll-agent outperforms numerous baselines and methods for long-context understanding AI agent systems.
Together, the camroll dataset and camroll-agent highlight the gap in AI agents' long-context reasoning: personalized visual memory requires different approaches from standard long-context textual memory, especially when consistency, visual details, and user-specific context are present.
dataset
- Dataset: 50 users, 31,476 images, 2,500 QA pairs — sourced from YFCC100M under each photo's original Creative Commons license and served by Flickr's CDN; nothing is re-uploaded.
- Manual annotations — every question/answer pair was hand-written to mimic real-world camera-roll usage, then grounded in the user's actual photos.
For dataset access, please contact yuhli@adobe.com and krishsin@adobe.com.
cite
@misc{camroll,
title={Personal AI Agent for Camera Roll VQA},
author={Thao Nguyen and Krishna Kumar Singh and Donghyun Kim and Yong Jae Lee and Yuheng Li},
year={2026},
eprint={2606.05275},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.05275},
}