Large Multimodal Models (LMMs) have shown remarkable capabilities across a variety of tasks (e.g., image captioning, visual question answering).
While broad, their knowledge remains generic (e.g., recognizing
Human reasoning, in contrast, typically operates within the context of specific subjects in our surroundings. For example, one might ask,
What should I buy for;my dog 's birthday?
What should I buy for.a dog 's birthday?
vs.my friend is holding a cat
.a man is holding a cat
Given a handful of images of a person or a subject I1, . . . , In (e.g., 5 images of your friend
Our goal is to embed this subject into a pre-trained LMM (in our case, LLaVA), so that both the user and model can communicate using an identifier (e.g.,
After being personalized, our method (Yo’LLaVA) can:
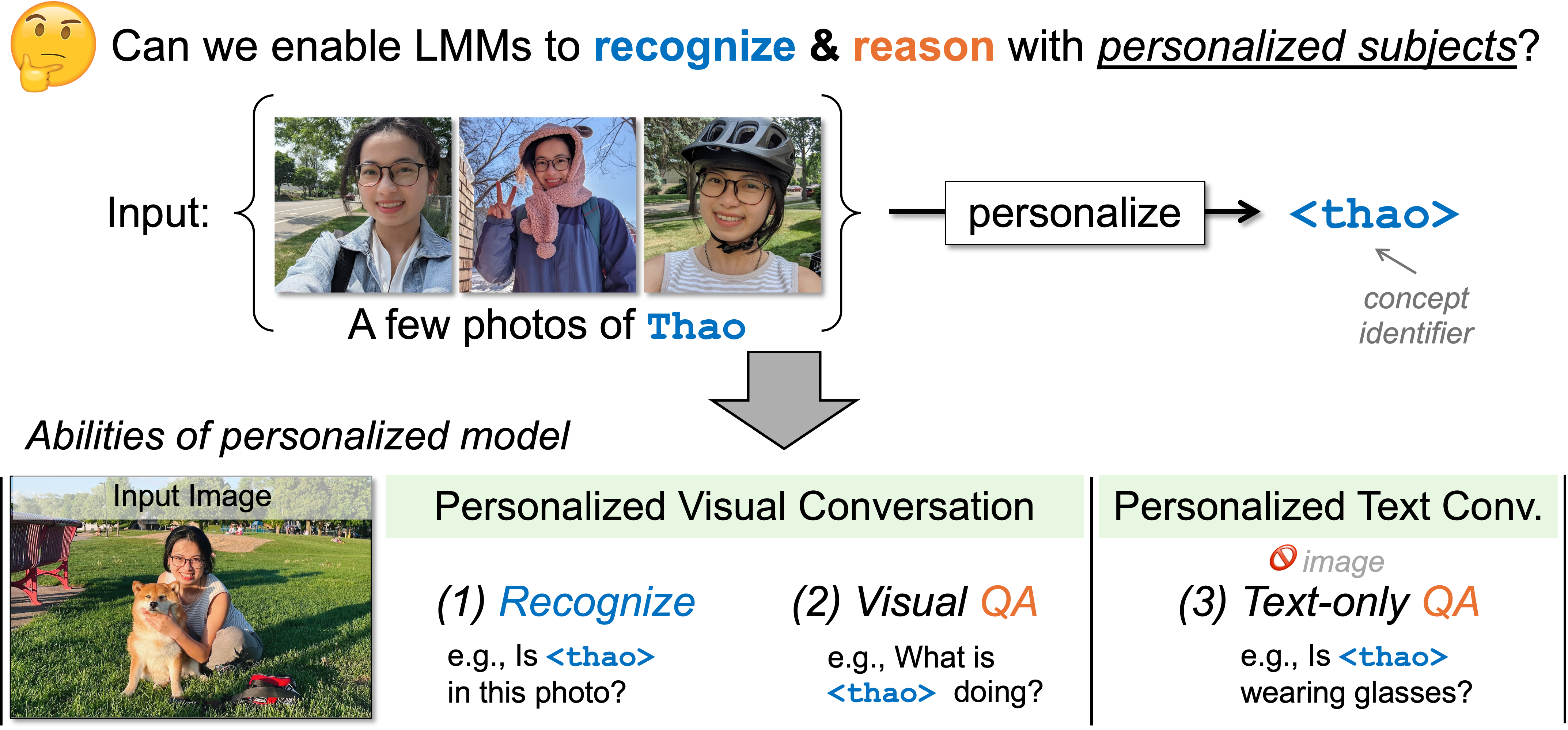

|

|

|

|

|

|
|
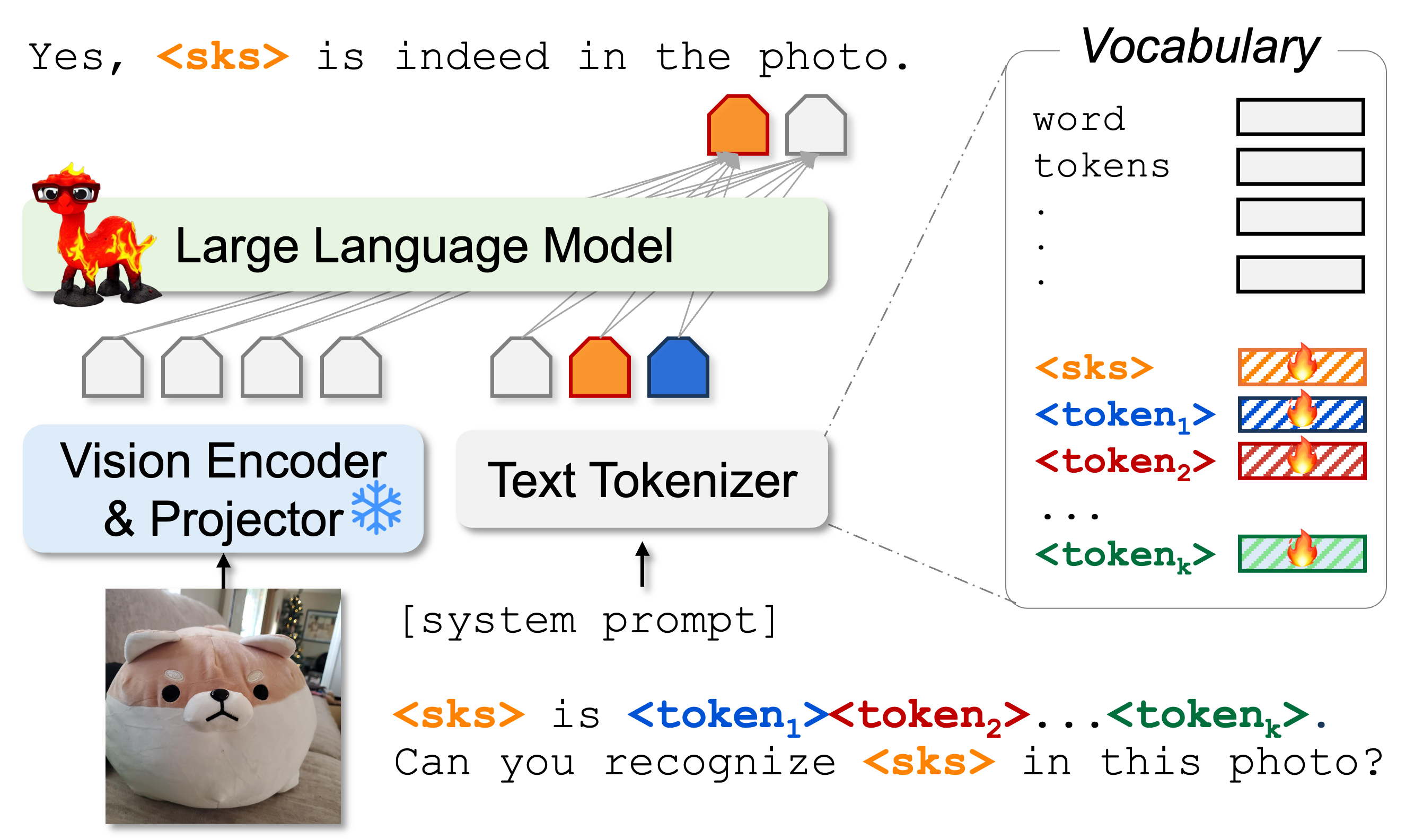
⚙️ Training Pipeline: We define a personalized soft-prompt for the subject as: Here, |
|
🛠 Training Dataset Creation:
To help the model learn the new visual concept, we generate conversational training data triplets {Image, Question, Answer}:  We create more generic conversations for training (e.g., visual Q&A), which focus on the subject’s visual characteristics. Note: No input image are given during training! |
|
@misc{nguyen2024yollavapersonalizedlanguagevision,
title={Yo'LLaVA: Your Personalized Language and Vision Assistant},
author={Thao Nguyen and Haotian Liu and Yuheng Li and Mu Cai and Utkarsh Ojha and Yong Jae Lee},
year={2024},
eprint={2406.09400},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2406.09400},
}
🤗 This work was supported in part by NSF CAREER IIS2150012, Adobe Data Science award, Microsoft Accelerate Foundation Models Research Program, and Institute of Information & communications Technology Planning & Evaluation (IITP) grants funded by the Korea government (MSIT) (No. 2022-0-00871, Development of AI Autonomy and Knowledge Enhancement for AI Agent Collaboration) and (No. RS-2022-00187238, Development of Large Korean Language Model Technology for Efficient Pre-training).
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.




